How to Write a High-Performance Resume with ChatGPT
Most candidates use ChatGPT to “write” their resumes, resulting in generic, fluff-heavy documents that professional recruiters—and ATS algorithms—can spot from a mile away. To stand out in the 2026 job market, especially for high-stakes roles like Data Engineering or Product Management, you must stop “writing” and start engineering.
At AI Career Lab, we’ve stress-tested an iterative methodology to reconstruct a raw career history into a high-performance, ATS-ready resume. Here is our step-by-step audit of the process using a real-world case study for a Senior Data Analyst (Audit Team) role at Intact Financial.
1. The Strategy: Reconstruct, Don’t Just Generate
The “Lab” approach moves away from single-prompt generation. Instead, we use an iterative framework:
- Context Injection: Building a knowledge base.
- Gap Analysis: Auditing the mismatch between your data and the JD.
- XYZ Reconstruction: Rebuilding bullet points using the Google-standard formula.
- ATS Pressure Test: Simulating the final filter.
We’ll use below JD as example to run ChatGPT for resume.

2. Phase 1: Context Injection (The Data Foundation)
A model is only as good as its training data. We began by feeding ChatGPT two distinct datasets: the Target Job Description (JD) and the Raw Career History.
Prompt to Use:
"I am going to provide two sets of data: a Target Job Description (JD) and my Raw Career History. I want you to act as a Senior Technical Recruiter. Your only task right now is to analyze both and acknowledge when you are ready. Do not write anything yet.
Target JD: [Paste the Intact Financial JD here]
Raw Background: [Paste your AX Energy and CT Bank background here]"The Setup
We defined the AI’s role immediately: “You are a Senior Technical Recruiter at Intact Financial. Your task is not to write yet, but to analyze.” By providing the specific JD—which emphasized key elements Snowflake, Databricks, and Audit-relevant ETL—the AI understood the “success criteria” before a single word was drafted.
3. Phase 2: Gap Analysis & Technical Translation
In this phase, we audited the raw background (Energy and Banking sectors) against the Intact Financial requirements.
Prompt to Use:
"Based on the JD, Intact Financial is looking for a hybrid between a Data Analyst and a Data Engineer, specifically for their Audit team.
List the top 5 technical 'must-haves' for this role.
Identify 3 areas in my raw background that align perfectly with their 'Audit & Compliance' context.
Identify any gaps where my raw background needs to be translated into 'Engineering' language (e.g., changing 'Reporting' to 'ETL' or 'Pipelines')."The “Audit” Findings:
- The Problem: The raw background used “Reporting” and “Dashboarding” language.
- The Opportunity: The Intact JD required “Data Development” and “ETL Engineering.”
- The Translation: We instructed the AI to translate “Weekly E-learning Scorecards” into “Automated Financial Security Data Pipelines.” This shifts the candidate’s perceived value from a Support role to a Technical Engineering role.
4. Phase 3: The Reconstruction (The Google XYZ Formula)
To ensure the resume was data-driven, we applied the Google XYZ Formula:
Accomplished [X] as measured by [Y], by doing [Z].
Case Study: Reconstructing the CT Bank Experience
Instead of saying “Responsible for automation,” our engineered output became:
“Modernized Compliance Scorecards by migrating workflows from Excel to Power BI, automating 100% of data refresh cycles and saving 50+ manual hours per year.”
Strict Lab Constraints:
- No Fluff: We banned words like “passionate,” “dedicated,” and “team player.”
- Hard Verbs: We forced the use of “Engineered,” “Architected,” and “Consolidated.”
Suggested Prompt to Use:
"Now, reconstruct the bullet points for my experience at CT Bank and AX Energy. Follow these strict constraints:
Framework: Use the Google XYZ formula for every bullet point.
Tone: Technical, authoritative, and objective.
Forbidden Words: Passionate, dedicated, hard-working, team-player.
Key Keywords to Integrate: ETL, SQL (CTEs/Sub-queries), Python Automation, Data Governance, Snowflake/Databricks context, and Auditability.
Focus: Frame my work at CT Bank as 'Financial Security Data Engineering' rather than just 'Training Coordination'."5. Phase 4: The ATS Stress-Test
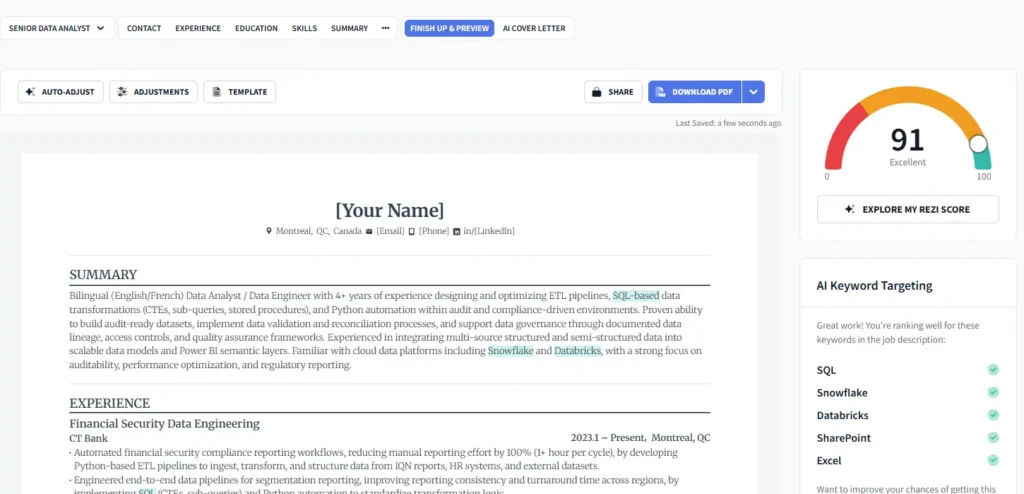
The final step in our lab test was a Simulated ATS Scan. We asked the AI to act as a Workday ATS algorithm to score the new resume against the Intact Financial JD.
Prompt to Use:
"I want you to simulate a Workday ATS (Applicant Tracking System). Scan the reconstructed resume against the Intact Financial JD.
Give me a 'Match Score' out of 100.
List the specific keywords that are still missing.
Suggest 2 final tweaks to the Professional Summary to ensure I am flagged as a 'Bilingual Data Professional' suitable for the Montreal market."The Lab Results:
- Match Score: 91/100 (Up from an estimated 72/100).
- Key Optimizations: The AI identified that while the technical skills (SQL, Python) were strong, we needed to emphasize “Bilingualism (English/French)” to meet the specific requirements of the Quebec/Montreal market.
6. The Final Verdict: Is ChatGPT Enough?
While ChatGPT is a powerful “Engine,” it still requires a Product Manager to guide it. Our test proved that:
- Iterative Prompting is non-negotiable.
- Domain Knowledge (knowing that “Audit” requires “Auditability”) must be manually injected.
- Final Formatting should still be handled by specialized tools (like Rezi) to ensure the LaTeX/PDF structure is 100% compliant.
Don’t Just Apply. Engineer.
Generic resumes get “Rekt” by modern ATS filters. Stop guessing and start using lab-tested frameworks to land your next interview.
Lab Resources:
Deep Dive: Audit the ChatGPT Prompts used in this case study.
The Verdict: Which AI tool is worth your investment? Read the Honest Review.